Comparing Top 3 AI Models for Salesforce Apex Code Reviews with GPTfy
Table of Contents
- TL;DR:
- Implementation in Salesforce with GPTfy
- Bring Any AI Models to Your Salesforce
- The Technical Architecture
- Key Takeaways
- Before and After: Developer Workflow
- Conclusion
- What's Next?
- Blogs you may find interesting
TL;DR:
I tested OpenAI GPT-4o, Anthropic Claude, and Google Gemini on the same Apex code review task with identical prompts. Each AI found different “critical issues” — GPT-4o focused on security, Claude on performance, and Gemini on validation — revealing that AI model selection significantly impacts your code review results.
Not a fan of reading articles? Check out the video here:
What?
A practical comparison of how three leading AI models (OpenAI GPT-4o, Anthropic Claude, and Google Gemini) analyze the same Salesforce Apex code with wildly different results.
Who?
Salesforce developers, architects, administrators, and technical leaders who want to understand how different AI models approach code analysis.
Why?
To help you decide which AI model best suits your Salesforce development workflow and quality standards.
→ Find the right AI for your code reviews and save development time while improving quality.
What can you do with it?
- Implement automated code quality reviews in your Salesforce org
- Compare different AI models for technical analysis effectiveness
- Set up a continuous code quality system for your development team
- Create a historical record of code improvements over time
Under the hood: The Experiment Setup
Using GPTfy, an AppExchange app that lets you connect any AI model to your Salesforce org, I created a system to analyze Apex code automatically. Here’s the setup:
- Created a custom object structure
- Configured a comprehensive prompt with coding standards and best practices
- Ran the same code through three different AI models
The goal was simple: see how different AI models would evaluate the exact same code using the exact same prompt.
The Results: Three Different Perspectives
OpenAI GPT-4o: The Security-Focused Reviewer
GPT-4o immediately identified a critical security issue: the absence of a sharing declaration in the class. This focus on security considerations before anything else shows GPT-4o’s tendency to prioritize access control and security vulnerabilities.
It provides clear explanations of why this was problematic and offers straightforward solutions.
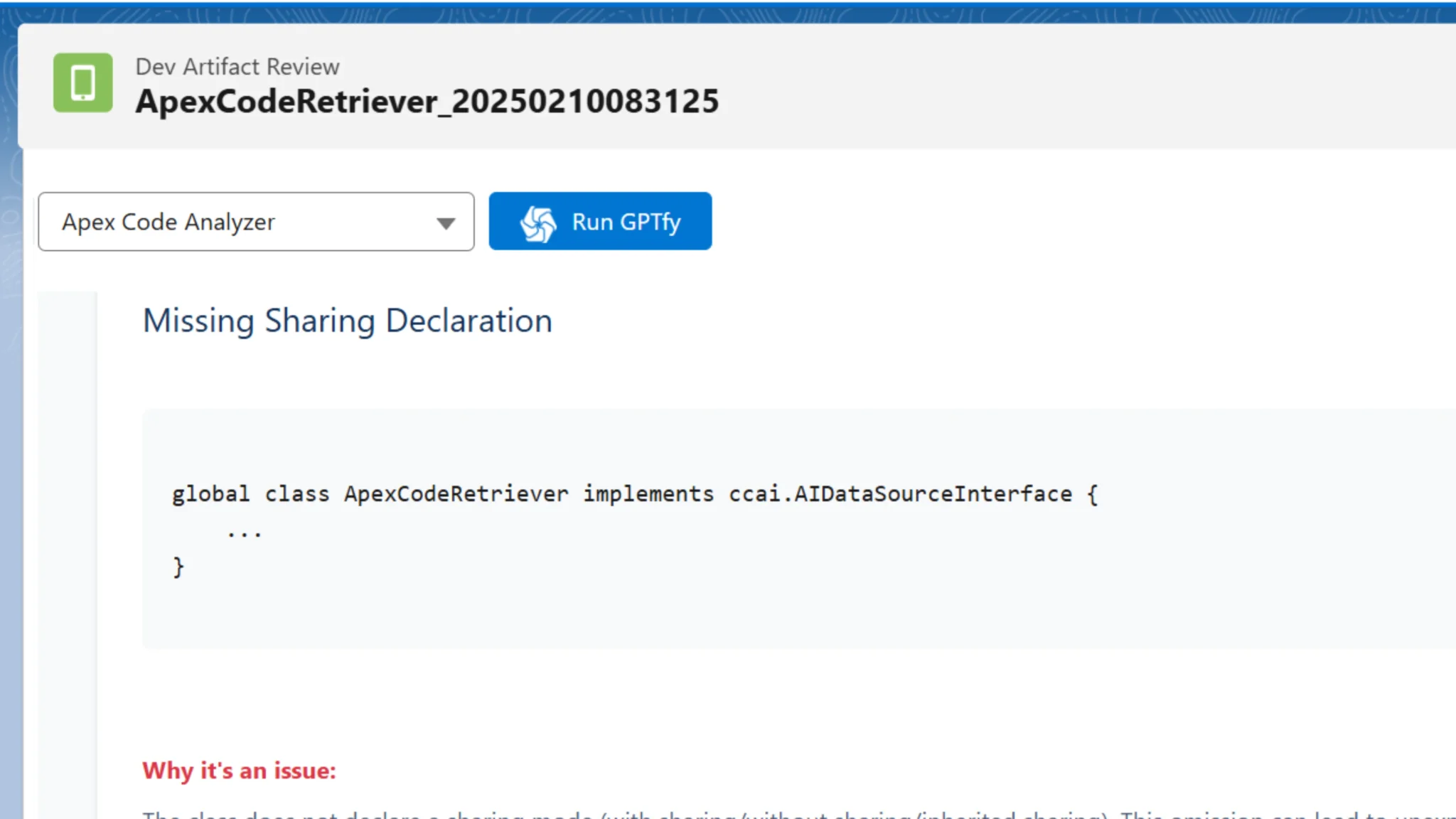
GPT-4o also found other issues but categorized them as “important” rather than “critical,” such as:
- Use of general exceptions instead of specific ones
- Lack of proper code commenting
What stood out was GPT-4o’s straightforward but slightly less detailed explanations compared to the other models.
Anthropic Claude: The Performance-Focused Mentor
Claude took a different approach, identifying SOQL queries within loops as the critical issue. This focus on performance and scalability over security shows Claude’s tendency to prioritize operational efficiency.
Claude’s explanations were notably more detailed and educational, almost like having a mentor review your code.
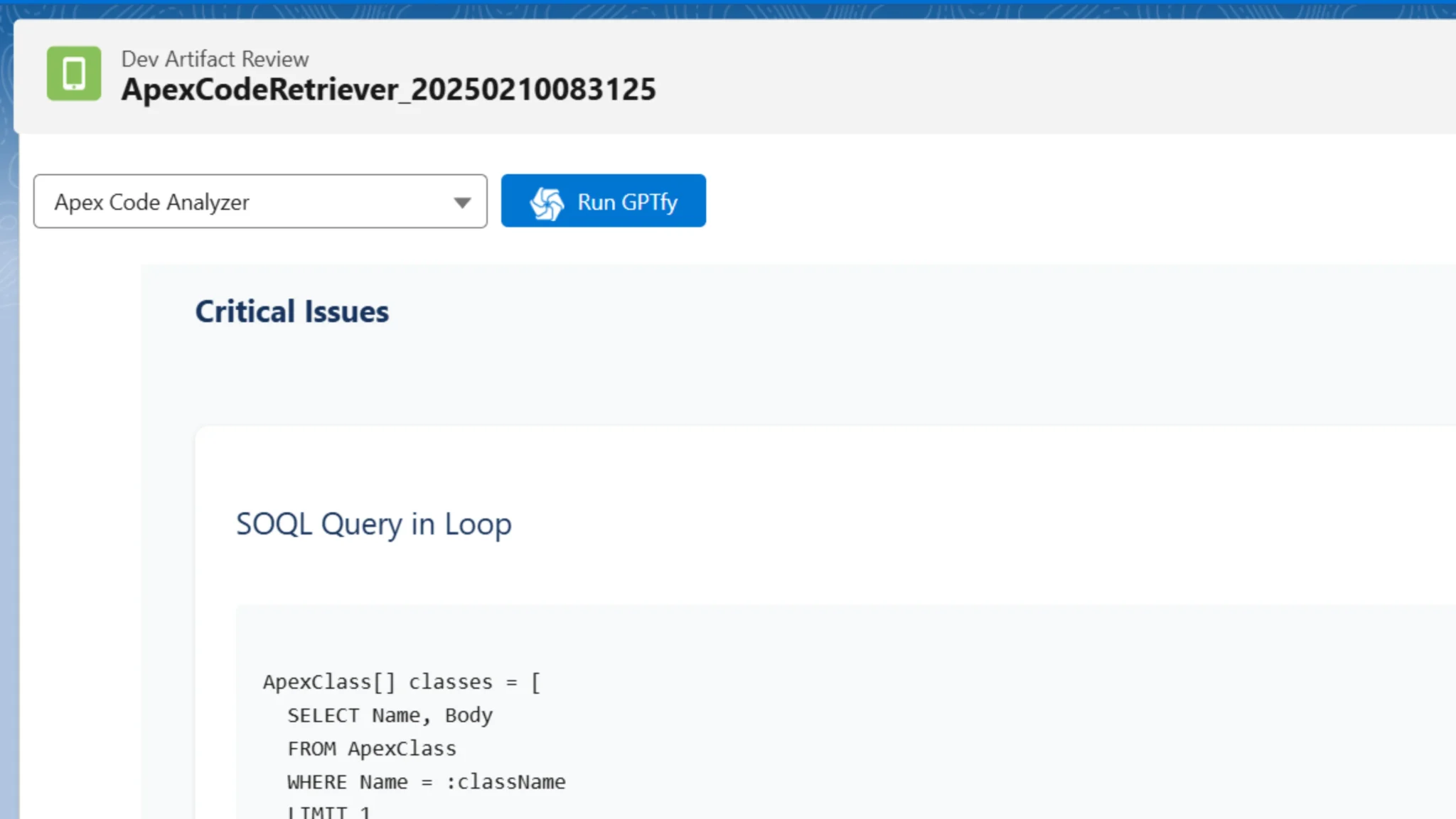
Claude’s code examples seemed more practical and thoughtful, and its explanations were more coach-like and user-friendly.
Google Gemini: The Quick but Quirky Assistant
Gemini was noticeably faster than the other models, but it exhibited some interesting quirks in its responses.
Its explanations sometimes stray off-topic, making unusual analogies or including irrelevant commentary. While Gemini seemed to prioritize input validation as its primary focus, its explanations were sometimes unclear or unfocused, less coherent. They sometimes contained confusing statements that weren’t directly related to the analyzed code.
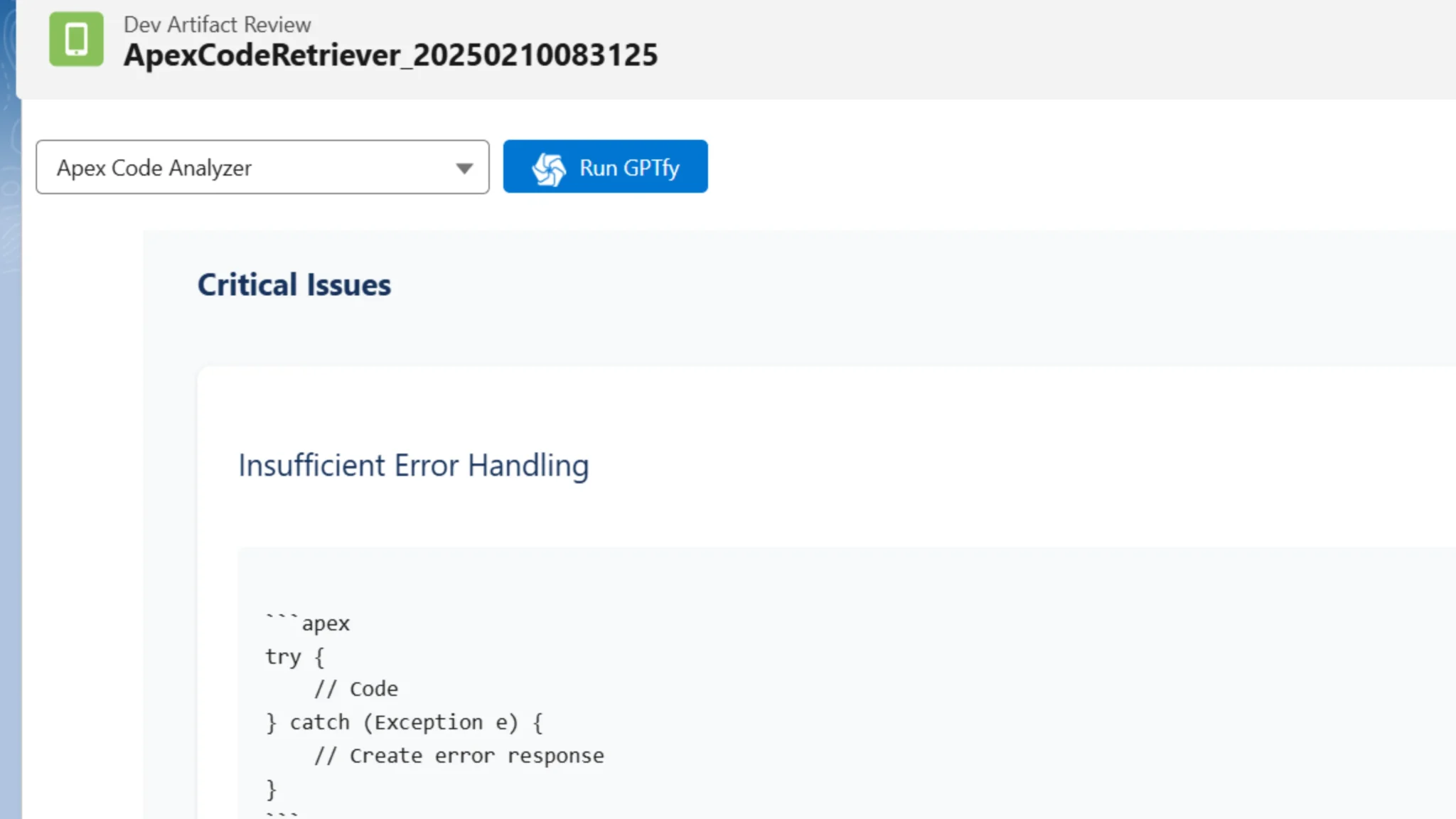
While speed might be Gemini’s advantage, the clarity and focus of its code review feedback lagged behind the other models in this specific use case.
Implementation in Salesforce with GPTfy
What makes this experiment particularly interesting is how easily you can switch between different AI models using a platform like GPTfy. Here’s how it works:
- Select your AI model in Salesforce: Choose from OpenAI, Anthropic Claude, Google Gemini, or others
- Configure your prompt in Salesforce: Set up a comprehensive prompt with your coding standards
- Run the analysis: Execute against any Apex class in your org
- Review the results: See how different models analyze your code
This flexibility lets you choose the right model for your specific needs or even run multiple models for a more comprehensive review.
Bring Any AI Models to Your Salesforce
Handle questions securely with AI. Works with Pro, Enterprise & Unlimited - your data never leaves Salesforce.
Get GPTfy
Read More here
The Technical Architecture
The implementation uses a simple but effective architecture:
- When a developer updates an Apex class:
- The system detects the change through a trigger or scheduled process
- It retrieves the code using Metadata API
- GPTfy sends the code to your chosen AI model
- The AI model analyzes the code based on your defined standards
- Results are stored in the custom object
- Developers can review the analysis and make improvements
Key Takeaways
This experiment revealed several important insights:
- Different models, different priorities: Each AI model has its own “personality” when it comes to code analysis. OpenAI prioritized security, Claude focused on performance, and Gemini emphasized input validation.
- Explanation quality varies: Claude provided the most detailed and educational explanations, while GPT-4o was more concise. Gemini’s explanations sometimes lacked focus.
- Speed considerations: Gemini was the fastest responder, which might be valuable in some scenarios even if the quality was less consistent.
- Prompt engineering matters: The quality of your prompt significantly affects the results. A well-crafted prompt with clear instructions produces better reviews regardless of the model.
- No one model rules them all: The “best” model depends on your priorities – whether you’re more concerned about security, performance, or other aspects of code quality.
Before and After: Developer Workflow
| Aspect | Before AI Code Reviews | After AI Code Reviews |
|---|---|---|
| Code Quality Checks | Manual, inconsistent | Automated, consistent |
| Review Time | Hours per class | Seconds per class |
| Coverage | Limited by reviewer bandwidth | Every class reviewed |
| Historical Tracking | Difficult to track improvements | Complete history of code evolution |
| Standards Enforcement | Varies by reviewer | Consistent application |
Conclusion
AI models can dramatically improve your Salesforce development process by providing automated code reviews, but different models have different strengths. OpenAI GPT-4o focuses on security issues, Anthropic Claude excels at performance optimization with detailed explanations, and Google Gemini offers speed but less consistent quality.
By integrating these AI capabilities directly into your Salesforce org with tools like GPTfy, you can implement a continuous code quality system that evolves with your development team and maintains a historical record of improvements.
Consider running multiple models against critical code for a more comprehensive review, or select the model that best aligns with your organization’s priorities.